

This is part of a series of blog posts where I’ll build out Continuous Integration and Delivery (CI/CD) pipelines using Azure DevOps, to test, document, and deploy Azure Data Factory.
Start with my first post on CICD for Azure Data Factory for an overview on the how and why.
If your Data Factory contains a self-hosted Integration runtime, you will need to do some planning work before everything will work nicely with CI/CD pipelines. Unlike all other resources in your Data Factory, runtimes won’t deploy cleanly between environments, primarily as you connect the installed runtime directly to a single Data Factory. (We can add more runtime nodes to a single Data Factory but we cannot share a single node between many data factories*). An excerpt from Microsoft’s docs on Continuous integration and delivery in Azure Data Factory mentions this caveat.

Warning message about IRs in Microsoft’s docs
When we deploy our ARM template using the continuous deployment (CD) pipeline we created in the last post, any integration runtimes will be deployed as they are. They will successfully create in the destination environment but self-hosted IRs are connected specifically from one machine (VM) to a single Data Factory. The actual keys and configuration of the IRs are built into each Data Factory and the ARM template simply deploys the reference to them. This means the IR won’t and can’t work in the destination Data Factory.

Migrated IR showing as unavailable
*We technically can, but I’ll explain how that can’t work below.
Options#
There are currently two viable routes to working around or solving this problem. One isn’t significantly better than the other and the one you choose will probably depend on your own usage of Data Factory, processes, and infrastructure. I’ll present both below with some quick Pros and Cons for each.
What about shared IRs?#
It is possible to share a self-hosted integration runtime (IR) with another, or several, Data Factories from the Sharing tab when you edit the IR. There’s a guide in docs to Create a shared self-hosted integration runtime in Azure Data Factory using the UI or PowerShell that walks you through how to do just that.
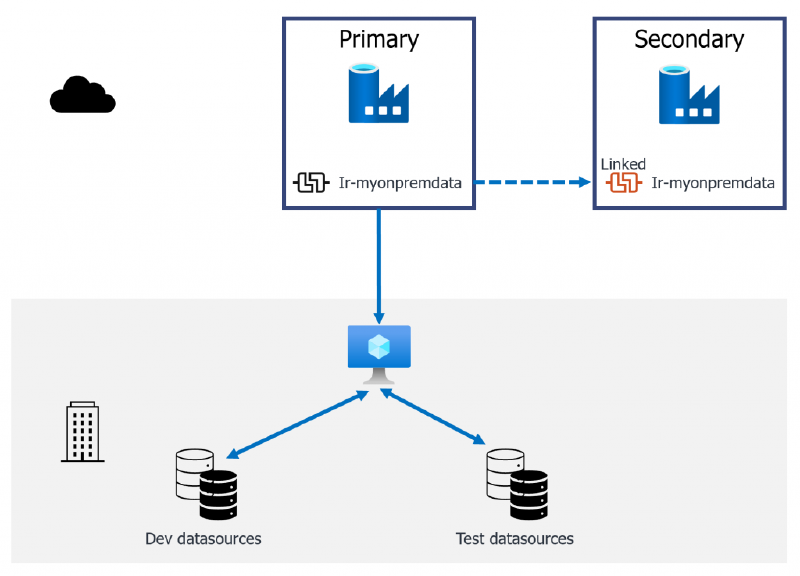
A Linked IR wont work in CI/CD pipelines
Sharing an IR retains the machine connection to your primary Data Factory and creates a Linked IR in the secondary Data Factory. The connection is still controlled from the primary Data Factory and removing it there will break the IR in the secondary too. This is a great way to cut down on VMs to host the IRs for non-production data sources for example, but this won’t work with our CI/CD pipelines.
If we are deploying to our Testing and Production environments using the CD pipeline, as described in the last post in this series, then this method won’t work. This is because the Integration runtimes are different “types” in the source and destination Data Factory.
{
"name": "[concat(parameters('factoryName'), '/ir-myonpremdata')]",
"type": "Microsoft.DataFactory/factories/integrationRuntimes",
"apiVersion": "2018-06-01",
"properties": {
"type": "SelfHosted",
"typeProperties": {
"linkedInfo": {
"resourceId": "[parameters('ir-myonpremdata_properties_typeProperties_linkedInfo_resourceId')]",
"authorizationType": "Rbac"
}
}
},
"dependsOn": []
}Looking at the JSON generated for a linked IR, there is additional properties for the linkedInfo detailing the resourceID and auth type which helpfully relates to a template parameter which points to our source Data Factory.
"ir-myonpremdata_properties_typeProperties_linkedInfo_resourceId": {
"type": "string",
"defaultValue": "/subscriptions/d9368466-XXXX-4d83-XXXX-bb9f336fb6a7/resourcegroups/ModernDataPlatform/providers/Microsoft.DataFactory/factories/cpo-adf-dev/integrationruntimes/ir-myonpremdata"
}The template deployment will fail when trying to deploy a self-hosted IR over a linked self-hosted IR.

ARM template deployment failure due to linked IR
If you change the name of the linked IR in your secondary environment, we just end up with our original problem of a newly created IR that is only linked to the primary Data Factory.
Shared Data Factory#
The first option I want to explore builds upon the use of linked IRs as described above. To get around the issue of type mismatch, we create a separate Data Factory. This shared factory will host all of the IRs we need to connect to Dev, Test, and Prod data. The IRs are then shared out to their respective environments, with a single, consistent name. When we deploy through the CD pipeline, the ARM template deploys a Linked IR with the name (ir_myonpremdata) from Development to Testing with no failure.
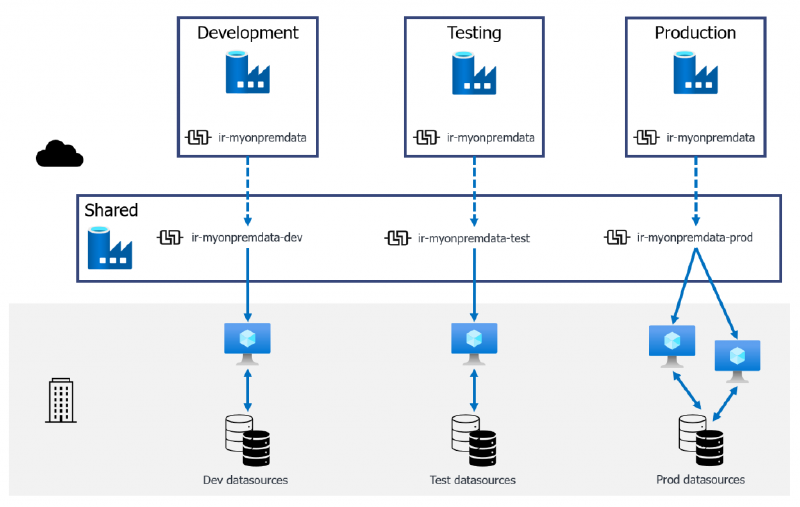
840A shared Data Factory linking IRs out to environment Data Factories
This approach also works with a reduced footprint by sharing out a single “non-production” IR to both Development and Testing Data Factories. Thus reducing the need for one of the virtual machines hosting the IR application.
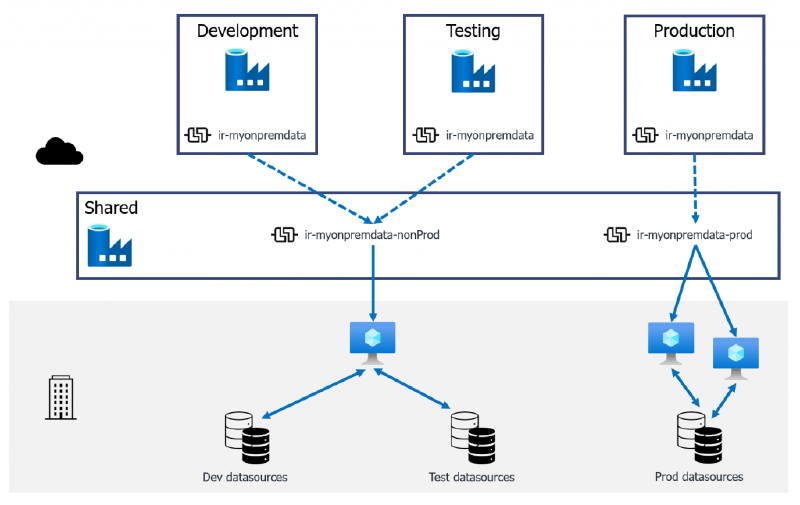
A shared Data Factory with a shared non-production IR
In both of the above scenarios I have Production data going through a 2-node IR to provide some redundancy and support for patching. It is possible to run everything through a single IR and VM (assuming your network is configured this way) and link that out to all of our Data Factories but that would be against best practices. It would also result in a single point of failure with development traffic potentially impacting production load times.
Pros#
- A single place to manage all self-hosted integration runtimes.
- Dev, Test and Prod environments can be destroyed and recreated with no minimal pre-creation steps needed. (assuming Dev is git integrated😉)
- Flexibility to reduce the VM footprint for installed IRs.
Cons#
- If the Shared Data Factory breaks or is deleted, you lose ALL connections!
- Its another Data Factory to manage.
- No option to secure the production and non-production IRs separately in the shared Data Factory.
To directly address the main Con here - a single point of failure, you can implement multiple shared data factory instances. This compounds the management overhead but if your organisation has multiple departments/projects or work streams, each requiring an isolated data factory to orchestrate data, then the scale advantage is there.
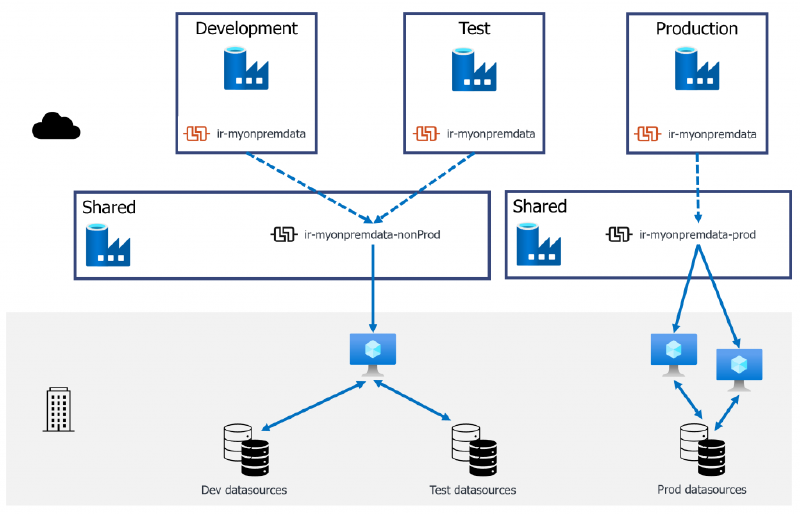
Multiple shared Data Factories to improve redundancy
Dedicated runtimes#
For this option we forego the shared Data Factory to host our runtimes. Instead we manually define them within each environment we’ll deploy between. The key thing here is that all of the IRs must have the same name just as in the previous example.
With all IRs created using the same name, the reference we deploy in the ARM template will match the configuration inside each Data Factory.
{
"name": "[concat(parameters('factoryName'), '/ir-myonpremdata')]",
"type": "Microsoft.DataFactory/factories/integrationRuntimes",
"apiVersion": "2018-06-01",
"properties": {
"type": "SelfHosted",
"description": "Self hosted IR installed on Data engineering VM",
"typeProperties": {}
},
"dependsOn": [
"[variables('factoryId')]"
]
},This won’t then impact the existing connection inside each environment, giving us the architecture shown below. This is a simpler option that is potentially more robust to failures but it is more rigid in its configuration.
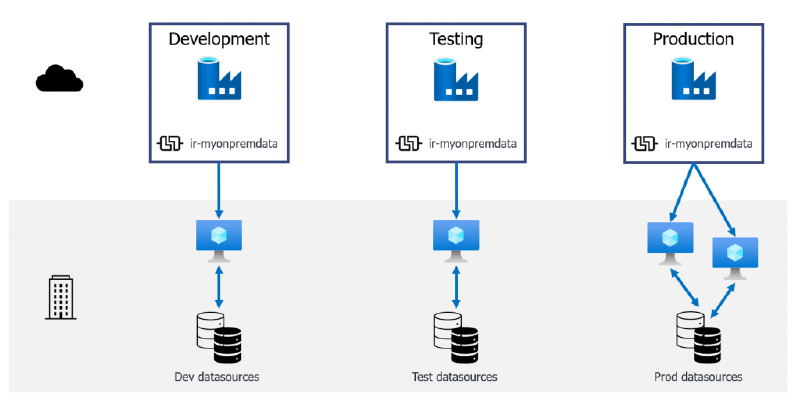
Individually defined IRs
Pros#
- Less resources to manage/support.
- Better control over security of each IR as they are defined in each environment.
- Each environment is separate with no shared dependency.
Cons#
- Manual set up of IRs needed within each environment.
- Inflexible configuration. No scope to reduce the number of VMs. This is at least one VM per environment.
Conclusion#
Both of these options have drawbacks and require some pre-planning. In a recent project I opted to implement the dedicated runtimes. This choice kept the overall architecture simpler and worked well where the organisation did not expect to scale out multiple instances of data factory for future projects.
If your organisation expects to utilise a dedicated data factory instance for individual projects, departments, or work streams for security or separation of duties then I’d recommend the Shared Data Factory approach as it is far more scalable.

