
This is the first in a series of blog posts where I’ll walk through the steps to build out Continuous Integration and Delivery (CI/CD) pipelines using Azure DevOps, to test, document, and deploy an Azure Data Factory. Links to each post are found below:
- CI/CD for Azure Data Factory: YAML deployment pipeline
- CI/CD for Azure Data Factory: How to handle self-hosted integration runtimes
- CI/CD for Azure Data Factory: Adding a Production deployment stage
At the end of the series we’ll have something like the process flow below.
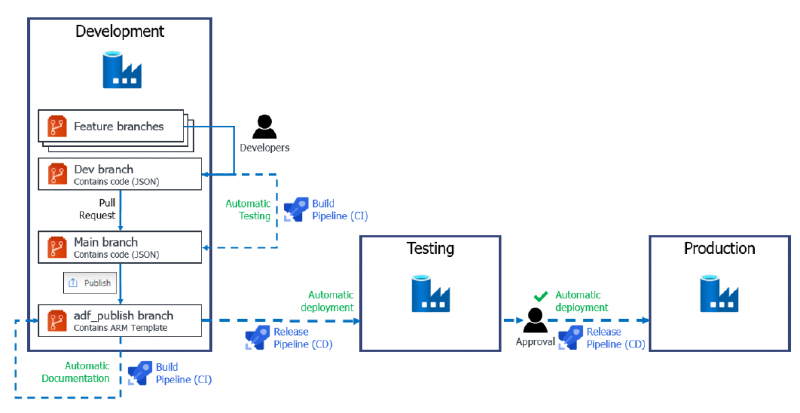
CI/CD pipelines with Azure Data Factory
#DontHateMe
I’m developing this as I learn and implement it myself. It may anger people that not all posts are available at once but if you get ahead of me and get inspired to build the rest yourself, I’d love to compare notes and explore the many options available. So get in touch in the comments and I’ll try not to keep you waiting.
Before we begin it’s important to know why you’d want to implement CI/CD for Data Factory, the benefits of it, and how you would go about doing it.
Why#
Microsoft have the following definition at the top of their Continuous Integration and Delivery for Data Factory page which sums up the “why” pretty well:
Continuous integration is the practice of testing each change made to your codebase automatically and as early as possible. Continuous delivery follows the testing that happens during continuous integration and pushes changes to a staging or production system.
In Azure Data Factory, continuous integration and delivery (CI/CD) means moving Data Factory pipelines from one environment (development, test, production) to another.https://docs.microsoft.com/en-us/azure/data-factory/continuous-integration-deployment#overview
With this definition in mind, our goal is to test everything we develop in Data Factory, utilise multiple environments, separated by use, and make the deployment between these environments as simple as possible so we end up with a reliable, trusted data engineering platform that’s easy to maintain. Lets consider some basics.
Separation of environments#
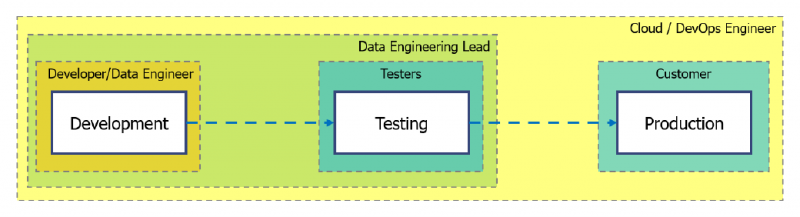
Regardless of the development process you use, an industry recognised best practice is the use of multiple environments. This helps to ensure any developed content is rigorously tested both technically and by the business, before it is made available to users or used in a production setting. A common approach is shown below.

An example of multiple environments
Applying this example to data engineering, Data Engineers develop and build pipelines in the Development environment. When these are in a working, stable state they are promoted to the Testing environment where the outputs can be tested by the customer, end users and/or BI developers. If no further development is needed, the pipelines can be deployed to Production. This gives us several stages and points of view to capture bugs, data quality issues and missing data before the end user interacts with what we’ve built.
There are many great technical reasons to implement multiple environments with any type of development;
- A Development, test, and production environment allows separation of duties and minimises impact from changes by other teams.
- Downtime and risk is minimised if development and testing are done on dedicated environments before being deployed to production.
- Security and permissions can be restricted per environment to reduce the risk of human error, data loss, and protect sensitive data.
Money#
If you are pitching this to your management, a customer, or client however, the most important arguement is always money. All of the above points and any others contribute to a monetary impact.
- If data isn’t being moved to where it is needed, when it is needed, that impacts profits.
- Sales teams don’t have the insights they need to make sales.
- Without the data on what is/has gone wrong, Support teams can’t fix issues.
- Deploying something without testing risks outages which means financial impact.
These, among many more reasons, is why we need proper development, testing, and production environments. CI/CD takes that a step further and gives us a way to automate administrative tasks and minimise the technical risk. More specifically, the human element. By automating and integrating testing and deployment we are ensuring the same actions happen each and every time in a consistent way. These processes won’t vary by team member, urgency of the change, or day of the week.
Security#
The key factor in this, for me, is plugging the gaps so the process can’t just be skipped when someone shouts loud enough. …And someone always does
Here’s a simplified example of a security model that you may implement across your environments. There’s a lot more detail around read/write permissions here but it give you an idea of the separation of duties. It keeps both data and environments secure.
Example environment security model
CI/CD#
Coming back to our definition at the start, by implementing CI/CD pipelines as part of our development process we can test and deploy our data pipelines automatically and consistently each time. A simplified view of how that process might look is shown below:

Simplified CI/CD pipeline
How#
With that quick overview on why you would want to implement CI/CD pipelines, lets get onto how we do it with Data Factory. We’ll start with some important steps we need to take to make it happen.
Prerequisites#
We’ll need at least two Azure Data Factories set up, for the Development and Testing environments. You can set up Production too if you don’t already have one. We also want to configure our development Data Factory in git integrated mode. Checkout the Source Control in Azure Data Factory docs for full details. There’s also a great video guide demo from Daniel Perlovsky

Provisioned Data Factories
To build our pipelines and store our code we will need an appropriate Azure DevOps project. As we’re using Azure DevOps for our build and release pipelines I’ll also use the built-in git repos but you can use GitHub if you prefer. The integration is quite consistent across both Azure DevOps and Azure Data Factory. You can create a DevOps project for free from the Azure DevOps homepage.
Azure DevOps new project view
Once we have these tools and resources in place we’re ready to start creating our pipelines. I start off with the deployment pipeline in the next post in this series.
Next up: CI/CD with Azure Data Factory: YAML deployment pipeline

