“Data Maturity is the measure of an organisations ability to successfully utilise the data they create to make data-driven decisions.”
There are a great number of factors that contribute to an organisation’s data maturity, both technical and non-technical. The non-technical factors often have the biggest impact however. Such as how open to change the business’s upper management is, how much data is embraced by department and team leaders, and the training and support provided to utilise new technologies. All of these factors set the expectation and appetite for change within the business much more than the role out of a new product or technology.
Data Personas are one such area that contribute greatly towards Data Maturity as they define responsibility and access beyond the roles and job titles of team members. Individual team members may fit multiple personas or none at all. There are five core Data Personas that need to be established within an organisation for effective data governance and management with some additional personas on the periphery that can map a bit more to specific technical roles. The number of personas will vary depending on the maturity of the organisation’s data platform and their use of data but the core personas are relevant to all organisations.
Core Personas#
- Data Engineer
- Data Analyst/Modeller
- Data Owner
- Data Steward
- Report/Data Consumer
Periphery Personas#
- Data Scientist
- Cloud/Azure Admin
- Data Platform Admin
- Data Architect
- Infrastructure Admin
- Super User
- Etc…

I’ll explore the core personas below and look at how they would interact with a data platform’s security model to give context to their responsibilities. This is a great way to help align personas to individuals, based on their expected interaction and control within the organisation’s data estate.
Specific permissions will always vary based on data source, sensitivity of the data and existing policies within an organisation so I generally group permissions into three categories. Read/Write for the most access and permissions on the data. Read access to denote a restricted view of the data with no permission to influence it, and finally No access where the persona should not need to access that data.
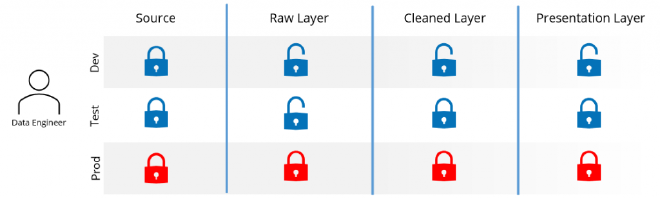
Data Engineer#
The Data Engineer is responsible for implementing and maintaining the data pipelines to bring data from source, through the organisation’s platform, and making it available to the Data Analyst/Modeller. They will build data transformations, validations, data quality checks, and analyse performance of data pipelines.
Generally it would be the responsibility of the Data Analyst to work out the business requirements for the data and relay those in a technical manner to the Data Engineer.
This personas has the widest technical expertise of all the core personas and this will be driven by the technologies present but generally SQL, Python, and spark knowledge would be fairly standard. Applying the persona’s responsibilities to a data platform’s security model, the Data Engineer would generally have enough freedoms in development environments to perform their role and also explore options to improve and develop new solutions. Read access would be relevant They would not generally have access to production systems or data.
Data Analyst / Modeller#
The Data Analyst or Modeller may be two distinct personas depending on the size and maturity of an organisations data estate. This persona bridges the gap between the business and data engineering to translate requirements into data pipelines. Data modelling is often considered part of the same persona as it builds upon the same skills.
This persona can map to a single role within a technical team but often encompasses a business analyst’s skillset with the technical skills of a Business Intelligence (BI) developer.
From the perspective of a security model, the Data Analyst would generally only have read access to cleaned data but more granular control over a presentation layer to serve data in a usable way to the Data/Report consumer. This would be further restricted going into a production environment.

Data Owner#
The Data Owner persona is generally fulfilled by someone close to how data within a specific domain (or department) is created or used. For example, a CRM system, although administered by a technical team will likely have owners within the respective areas of the business who work directly with the data in those systems. Be that Sales, Marketing, etc. The Data Owner persona aligns much closer to that business application owner but there must be the awareness of how the data can be used and what limits the use of that data (such as data quality).
Generally, the Data Owner would be responsible for controlling access to their data domain, make decisions on maintaining and achieving good data quality, as well as monitoring how the data is used throughout the organisation. The day-to-day management of data quality, requests, and initiatives within a data domain would be handled by a Data Steward, which I describe next.
With our security model, the Data Owner would have read access to the source data for their data domain. Generally they wouldn’t have access to the data platform but in some cases the Data Owner may have read permissions to the cleaned and presentation layers for data quality reviews and verification of outputs.

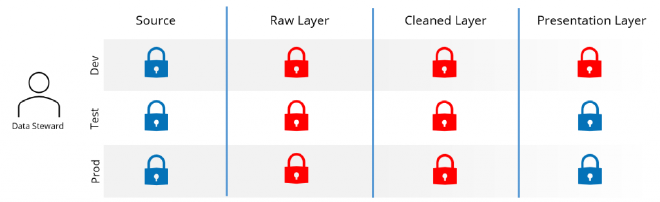
Data Steward#
As mentioned above, the Data Steward is a hands-on extension of the Data Owner role, managing the day-to-day elements of their data domain.
A key part of making this persona work within the organisation is establishing feedback loops. The Data Steward needs to understand the quality of their data and the problems Data Consumers and Analysts are encountering with it. This would take the shape of a regular data governance forum within a mature organisation but I won’t cover those here.
The security model for a Data Steward is going to be similar to that of the Data Owner but would likely be more restricted on the data platform due to this primarily being a business persona.
Data Consumer#
The Data or Report Consumer persona is essentially your end user. Although I use the nomenclature of “consumer”, a key function of this persona is creating reports (self-service reporting), using data presented by our Data Analysts. This persona is the customer for your data estate and ultimately the test for every other persona in the chain. The data they use needs to be of sufficient quality and accessibility for them to do their job and they need a way to feed that back to the right people.
In more mature and larger organisations you can introduce a Super User persona that collects feedback from within consumer teams across the business (your data community) which is fed back through a forum.
From a security perspective, the Data Consumer has the least privileges in the data platform with read access to the presentation layer and likely the same access in Test, although this may be limited to specific requests/projects.

Periphery Personas#
I mention “Periphery Personas” at the start and in most cases the requirement for these will vary greatly depending on a number of factors, such as your technology stack, business sector/focus, organisation size, and data maturity. Establishing the core personas is key to establishing a data-focussed organisation. As you progress on that journey there may be scenarios where those personas branch out to better establish clear responsibilities.